Data Challenge Lab Home
Spatial basics [wrangle]
(Builds on: List columns)
(Leads to: Spatial visualisation)
Spatial packages
In R, there are two main lineages of tools for dealing with spatial data: sp and sf.
-
sp has been around for a while (the first release was in 2005), and it has a rich ecosystem of tools built on top of it. However, it uses a rather complex data structure, which can make it challenging to use.
-
sf is newer (first released in October 2016!) so it doesn’t have such a rich ecosystem. However, it’s much easier to use and fits in very naturally with the tidyverse, and the ecosystem around it will grow rapidly.
In this class, we’re going to use sf, so start by installing it:
install.packages("sf")
Loading data
To read spatial data in R, use read_sf(). The following example reads an example dataset built into the sf package:
library(tidyverse)
library(sf)
# The counties of North Carolina
nc <- read_sf(system.file("shape/nc.shp", package = "sf"),
quiet = TRUE,
stringsAsFactors = FALSE
)
I recommend always setting quiet = TRUE and stringsAsFactors = FALSE.
Here we’re loading from a shapefile which is the way spatial data is most commonly stored. Despite the name a shapefile isn’t just one file, but is a collection of files that have the same name, but different extensions. Typically you’ll have four files:
-
.shpcontains the geometry, and.shxcontains an index into that geometry. -
.dbfcontains metadata about each geometry (the other columns in the data frame). -
.prfcontains the coordinate system and projection information. You’ll learn more about that shortly.
read_sf() can read in the majority of spatial file formats, so don’t worry if your data isn’t in a shapefile; the chances are read_sf() will still be able to read it.
Converting data
If you get a spatial object created by another package, us st_as_sf() to convert it to sf. For example, you can take data from the maps package (included in base R) and convert it to sf:
library(maps)
#>
#> Attaching package: 'maps'
#> The following object is masked from 'package:purrr':
#>
#> map
nz_map <- map("nz", plot = FALSE)
nz_sf <- st_as_sf(nz_map)
Data structure
nc is a data frame, and not a tibble, so when printing, it’s a good idea to use head() so you only see the first few rows:
head(nc)
#> Simple feature collection with 6 features and 14 fields
#> geometry type: MULTIPOLYGON
#> dimension: XY
#> bbox: xmin: -81.74107 ymin: 36.07282 xmax: -75.77316 ymax: 36.58965
#> epsg (SRID): 4267
#> proj4string: +proj=longlat +datum=NAD27 +no_defs
#> AREA PERIMETER CNTY_ CNTY_ID NAME FIPS FIPSNO CRESS_ID BIR74
#> 1 0.114 1.442 1825 1825 Ashe 37009 37009 5 1091
#> 2 0.061 1.231 1827 1827 Alleghany 37005 37005 3 487
#> 3 0.143 1.630 1828 1828 Surry 37171 37171 86 3188
#> 4 0.070 2.968 1831 1831 Currituck 37053 37053 27 508
#> 5 0.153 2.206 1832 1832 Northampton 37131 37131 66 1421
#> 6 0.097 1.670 1833 1833 Hertford 37091 37091 46 1452
#> SID74 NWBIR74 BIR79 SID79 NWBIR79 geometry
#> 1 1 10 1364 0 19 MULTIPOLYGON(((-81.47275543...
#> 2 0 10 542 3 12 MULTIPOLYGON(((-81.23989105...
#> 3 5 208 3616 6 260 MULTIPOLYGON(((-80.45634460...
#> 4 1 123 830 2 145 MULTIPOLYGON(((-76.00897216...
#> 5 9 1066 1606 3 1197 MULTIPOLYGON(((-77.21766662...
#> 6 7 954 1838 5 1237 MULTIPOLYGON(((-76.74506378...
head(nz_sf)
#> Simple feature collection with 6 features and 1 field
#> geometry type: POLYGON
#> dimension: XY
#> bbox: xmin: 166.458 ymin: -46.91705 xmax: 175.552 ymax: -36.09273
#> epsg (SRID): 4326
#> proj4string: +proj=longlat +datum=WGS84 +no_defs
#> geometry ID
#> 1 POLYGON((166.457992553711 -... Anchor.Island
#> 2 POLYGON((174.259948730469 -... Arapawa.Island
#> 3 POLYGON((166.580032348633 -... Coal.Island
#> 4 POLYGON((167.579833984375 -... Codfish.Island
#> 5 POLYGON((173.906433105469 -... D'Urville.Island
#> 6 POLYGON((175.535934448242 -... Great.Barrier.Island
This is an ordinary data frame, with one exception: the geometry column. This column contains simple features, a standard way of representing two dimesional geometries like points, lines, polygons, multilines, and multipolygons. Multilines and multipolygons are nededed to represent geographic phenomena like a river with multiple branches, or a state made up of multiple islands.
nc$geometry
#> Geometry set for 100 features
#> geometry type: MULTIPOLYGON
#> dimension: XY
#> bbox: xmin: -84.32385 ymin: 33.88199 xmax: -75.45698 ymax: 36.58965
#> epsg (SRID): 4267
#> proj4string: +proj=longlat +datum=NAD27 +no_defs
#> First 5 geometries:
#> MULTIPOLYGON(((-81.4727554321289 36.23435592651...
#> MULTIPOLYGON(((-81.2398910522461 36.36536407470...
#> MULTIPOLYGON(((-80.4563446044922 36.24255752563...
#> MULTIPOLYGON(((-76.0089721679688 36.31959533691...
#> MULTIPOLYGON(((-77.2176666259766 36.24098205566...
Use plot() to show the geometry. You’ll learn how to use ggplot2 for more complex data visualisations in the next unit.
plot(nc$geometry)
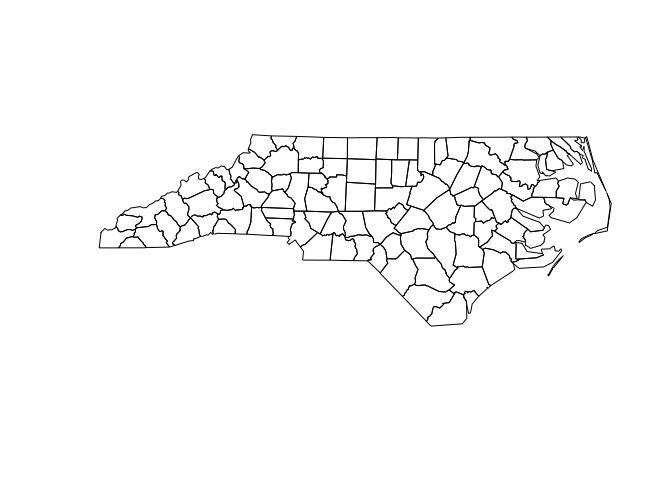
Manipulating with dplyr
Since an sf object is just a data frame, you can manipulate it with dplyr. The following example gives you a taste:
nz_sf %>%
mutate(area = as.numeric(st_area(geometry))) %>%
filter(area > 1e10)
#> geometry ID area
#> 1 POLYGON((172.74333190918 -3... North.Island 113469632351
#> 2 POLYGON((172.639053344727 -... South.Island 150444467051
st_area() returns an object with units (i.e. m2), which is precise, but a little annoying to work with. I used as.numeric() to convert to a regular numeric vector.
Geometry
The geometry column is a list-column. You’ll learn more about list-columns later in the course, but in brief, they’re the richest and most complex type of column because a list can contain any other data structure, including other lists.
It’s worthwhile to pull out one piece so you can see what’s going on under the hood:
str(nc$geometry[[1]])
#> List of 1
#> $ :List of 1
#> ..$ : num [1:27, 1:2] -81.5 -81.5 -81.6 -81.6 -81.7 ...
#> - attr(*, "class")= chr [1:3] "XY" "MULTIPOLYGON" "sfg"
plot(nc$geometry[[1]])
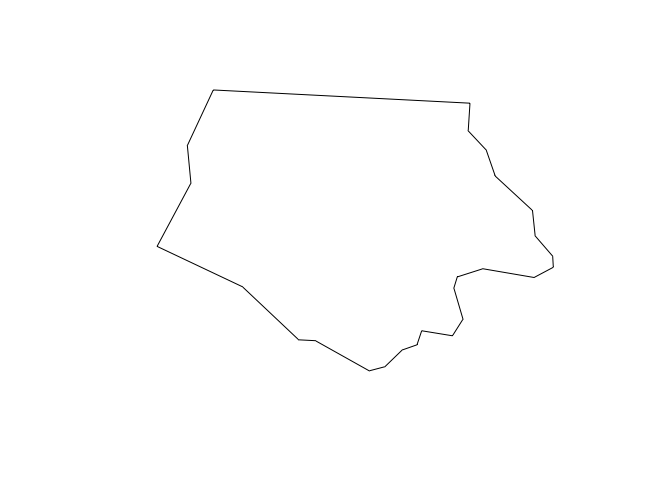
Note the use of [[ to extract a single element, here, the first polygon.
This is list of lists of matrices:
-
The top-level list has one element for each “landmass” in the county. We can find a more interesting case:
n <- nc$geometry %>% map_int(length) table(n) #> n #> 1 2 3 #> 94 4 2 interesting <- nc$geometry[n == 3][[1]] plot(interesting)
str(interesting) #> List of 3 #> $ :List of 1 #> ..$ : num [1:26, 1:2] -76 -76 -76 -76 -76.1 ... #> $ :List of 1 #> ..$ : num [1:7, 1:2] -76 -76 -75.9 -75.9 -76 ... #> $ :List of 1 #> ..$ : num [1:5, 1:2] -75.9 -75.9 -75.8 -75.8 -75.9 ... #> - attr(*, "class")= chr [1:3] "XY" "MULTIPOLYGON" "sfg"This is a county made up of three non-contiguous pieces.
-
The second-level list is not used in this dataset, but is needed when you have a landmass that contains an lake. (Or a landmass that contains an lake which has an island which has a pond).
-
Each row of the matrix gives the location of a point on the boundary of the polygon.
Coordinate system
To correctly plot spatial data, you need know exactly what the numeric positions mean, i.e. what are they in reference to? This is called the coordinate reference system or CRS. Often spatial data is described in terms of latitude and longitude. You can check this with st_is_longlat():
st_is_longlat(nc)
#> [1] TRUE
You might think that if you know the latitude and longitude of a point, you know exactly where it is on the Earth. However, things are not quite so simple, because latitude and longitude are based on the assumption that the Earth is a smooth ellipsoid, which is not true. Because different approximations work better in differently places, most countries have their own approximation: this is called the geodetic datum, or just datum for short.
Take two minutes and watch this simple explanation of the datum: https://www.youtube.com/watch?v=xKGlMp__jog
To get the datum and other coordinate system metadata, use st_crs():
st_crs(nc)
#> $epsg
#> [1] 4267
#>
#> $proj4string
#> [1] "+proj=longlat +datum=NAD27 +no_defs"
#>
#> attr(,"class")
#> [1] "crs"
Here the datum is “NAD27”, the North American Datum of 1927 (NAD27)
In this class, you won’t have to worry too much about the datum as sf and ggplot2 will take care of the details for you. But it’s good to know why it exists and how to identify it if something goes wrong.